There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
Troubleshooting a caching issue as you might know is usually not very straightforward. There are different layers of caching, and that could cause your asset to be cached in the end-user's browser, a CDN/proxy, or even in memory in the origin server.
About this post
The goal of this post is to give an overview of the first two (user's browser and CDN/proxy layers) because even though there are different browsers and CDN services, most of them work pretty much the same way according to HTTP standards. This post will not explain memory caching in the origin server as that usually varies depending on the tech stack.
There is a lot of information about HTTP caching out there, but they usually get very complex and in my experience, you will only need to understand the basics to be able to deal with most caching issues.
Why caching in the first place?
There are usually two main reasons to implement caching:
- Reduce server's load (by preventing it from responding with the same HTTP response multiple times, which could include CPU processing, queries to the database, etc).
- Improve the experience for end user (by reducing or getting faster network calls).
How does your browser fetch assets?
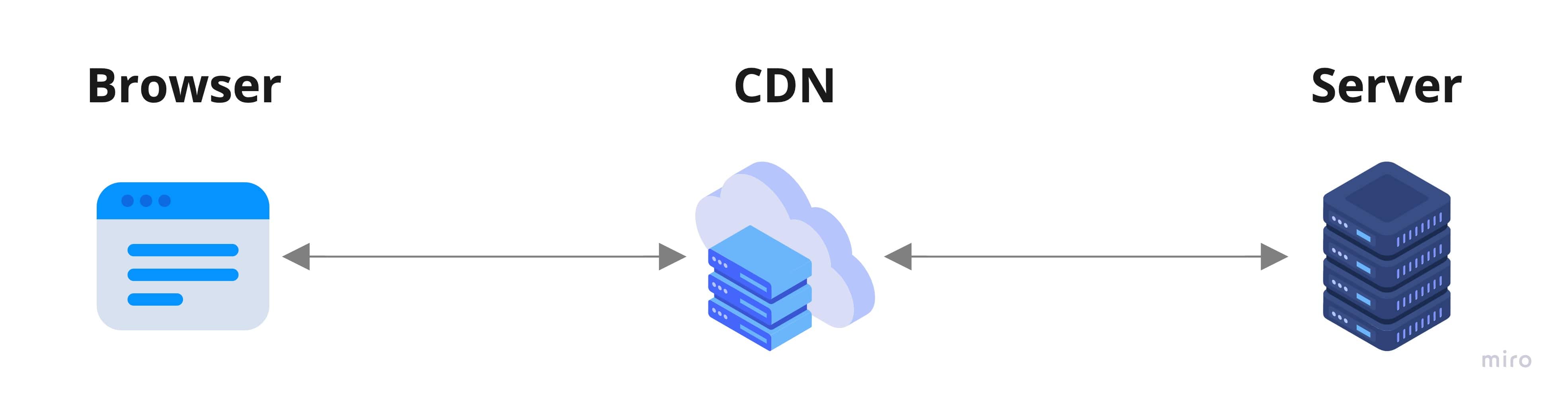
When your browser needs a resource (e.g: an image, a static HTML response, a JS file, etc) there are usually three actors involved:
- Browser
- CDN
- Server
The best case is always the browser having the resource already (no network requests involved), and the worst case is having to request the server for it.
The time cost of getting the resource from the origin server instead of the CDN is not only the processing time involved by the server, but also the latency caused by the end user being geographically far from it. That problem is reduced by having the CDN (e.g: Cloudfront, Cloudflare, etc) providing edge locations serving the requested resource to reduce that distance.
Depending on the stage of the flow, the CDN can either be providing an asset (when responding to the browser) or requesting it (when missing it from its local cache and calling the server for it).

From now on I will call consumer the actor that fetches the asset (browser or CDN), and provider the actor that retrieves it (CDN or Server).
How does caching works?
The usual way both your browser and the CDN know when and how to cache a resource is by this data included in HTTP headers:
- Max-Age and Age: Answers "Is this resource still fresh?"
- Etag: Answers "Has this resource changed?"
Knowing whether a resource is fresh or stale allows the consumer to know whether they can use the cached version or they need to make a network call to fetch a fresh one.
When the resource is stale and there is a network call to fetch a fresher version, the consumer will include in the request the version it has cached (Etag) for the provider to know whether it needs to send the newer version (if it changed) or respond with 304 Not Modified (it did not change).
Max-age and Age
They allow the consumer to know whether a resource is stale or not.
- max-age: Specifies how long the asset can be cached for (expressed in seconds)
- age: Specifies how long the asset has been cached for (expressed in seconds)
* Note there are other alternatives to "age" such as "date" or "expires", but I will focus on the first one as it is the most widely used in my experience
When the consumer needs to fetch a resource, it will first check whether there is already a cached version and what the max-age and age values are.
When the difference between them is positive (max-age - age > 0), it means the resource is still fresh and the consumer will reuse the cached resource without the need for a network request.
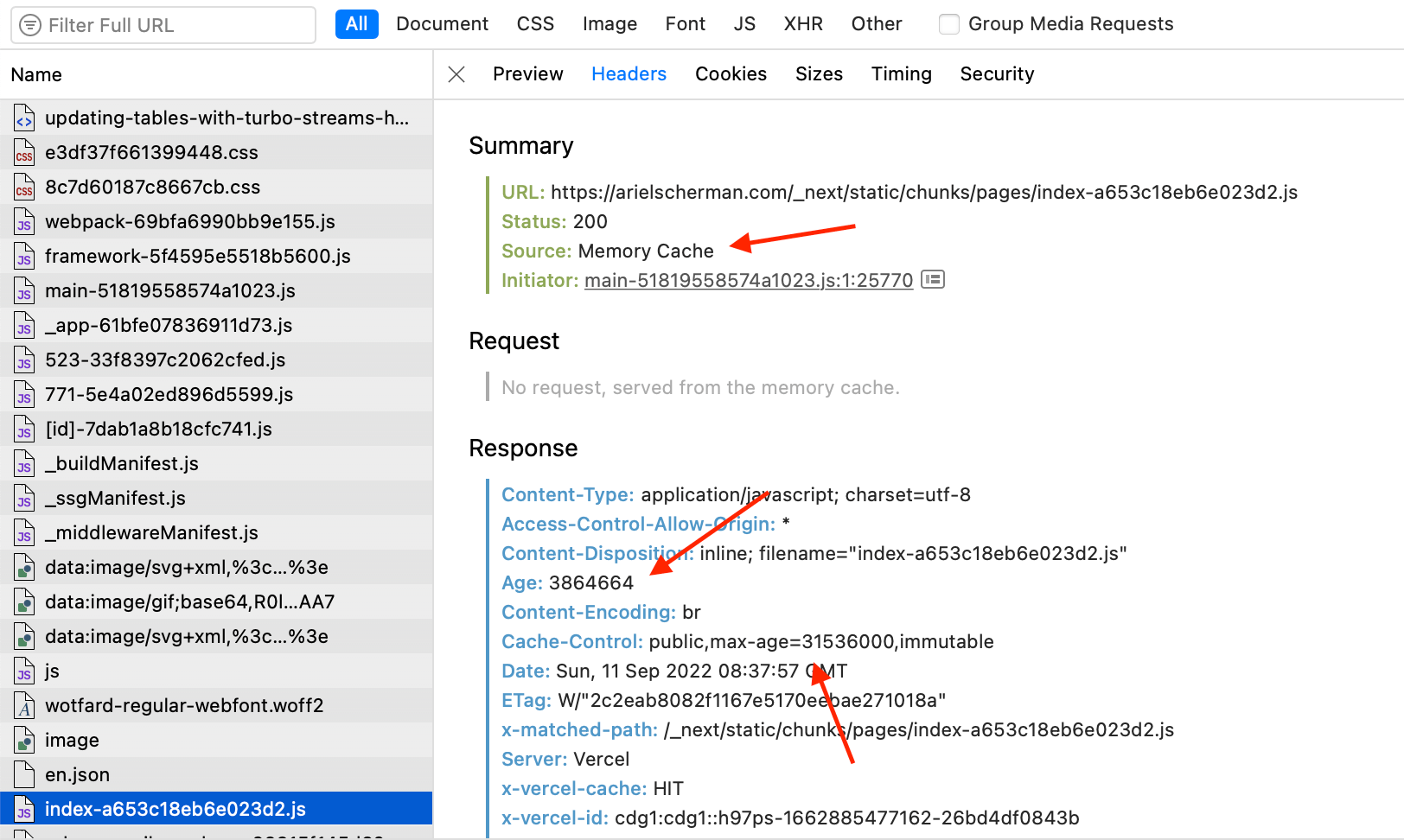
The example above is taken from a JS file of this website fetched by my browser. You can see that max-age is higher than age, which causes the resource to be retrieved from memory.
There will be no network requests until the max-age has passed.
If the resource is stale (max-age - age <= 0), the consumer needs to revalidate it, and that is where Etags come to help.
Etag
Typically, the ETag value is a hash of the content, a hash of the last modification timestamp, or just a revision number
-- MDN Web Docs
Etags are a way to identify a unique version of a given asset. Every time there is a change to a resource, its Etag changes.
When consumers need a resource that became stale in their local cache, they will fetch it again but including an If-None-Match header with the Etag of the cached version.
The provider will check whether the If-None-Match hash matches the one stored in its local cache.
- If it does not match, the provider will return the new version of the resource to the consumer (with the new Etag).
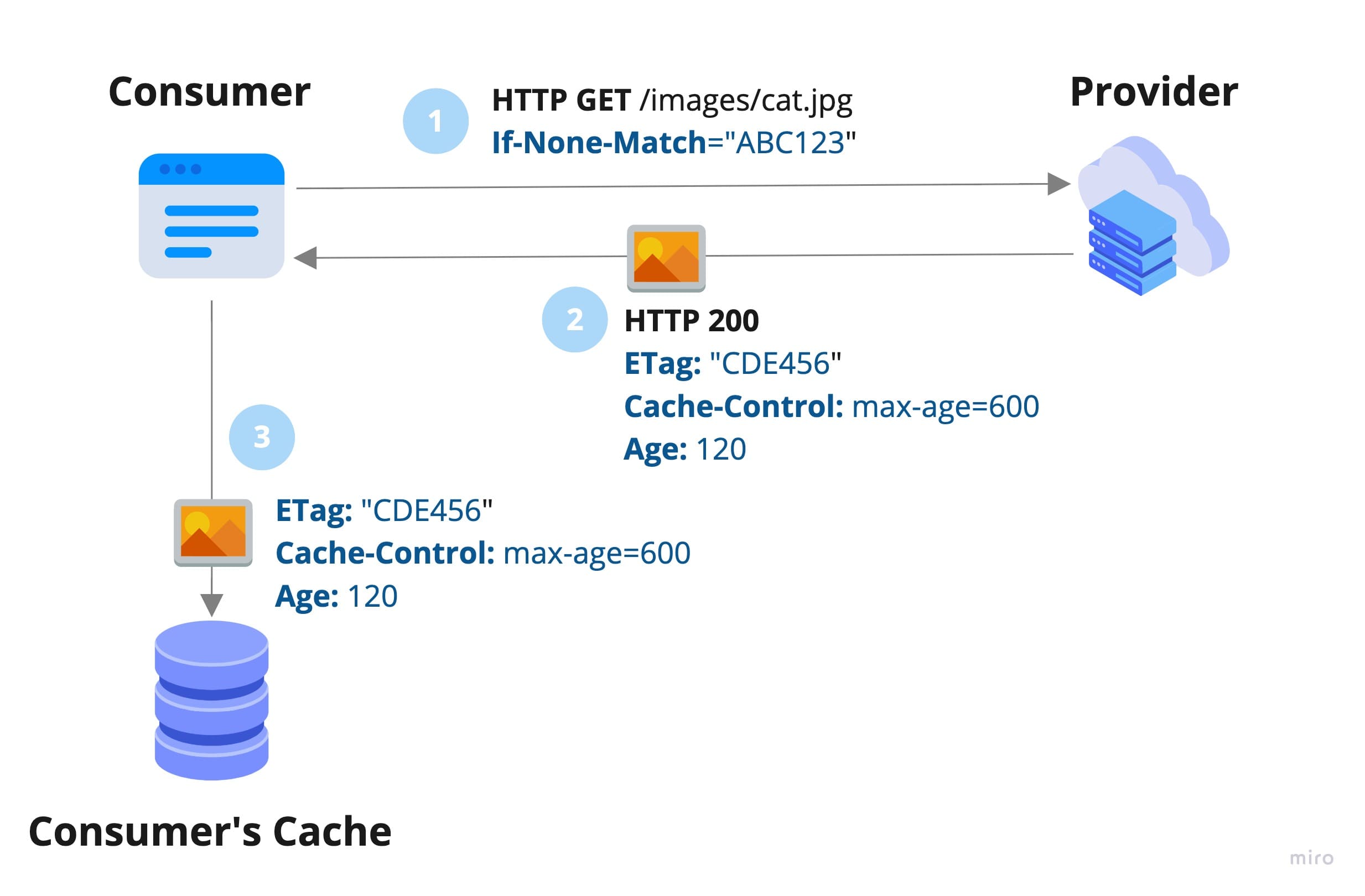
- If it matches, the provider will return a lightweight
HTTP 304 - Not Modifiedresponse which means the consumer should reuse the cached version it already has.

This flow is great because the response of images that have not changed are very lightweight

An example with the CDN as a middleman
When having a CDN as a middleman, it will fetch the resource from the server once, and then reuse it to respond to all browser requests with the cached one until it becomes stale. That reduces the number of requests to the server.
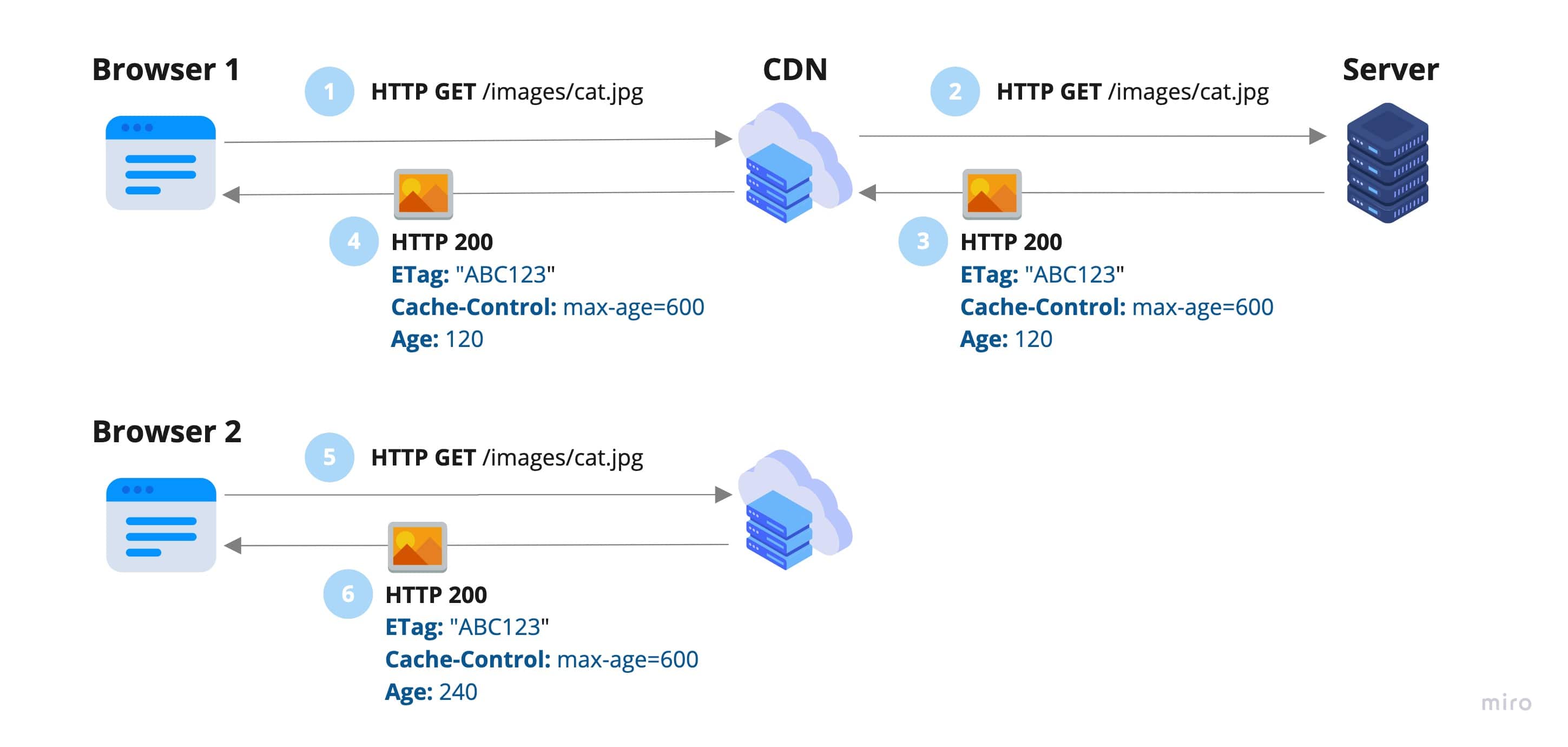
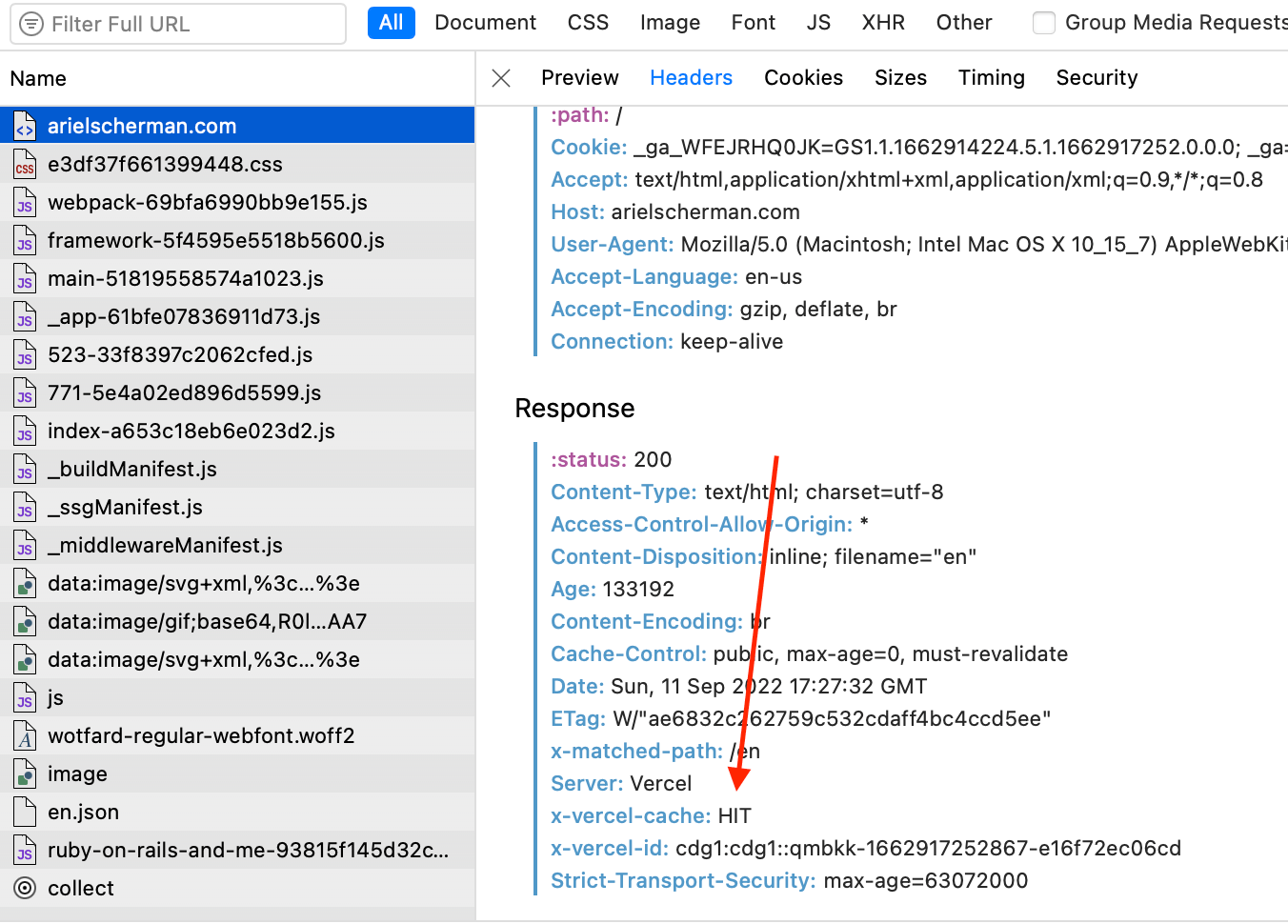
All CDNs add a header to the HTTP response to specify whether the request HIT the cache (meaning it retrieved the cached resource without even making a request to the server) or MISS (meaning the CDN either does not have fetched the resource yet, or it got stale).
As an example, this is the header used by vercel CDN, where you can see it used the asset stored in its local cache:
Summary
HTTP Caching is used to fetch resources way faster and reduce server load at the same time. This is done by both having the browser reusing assets instead of making a network request, and by placing a CDN with edge locations that both serve resources closer to end users to reduce latency. CDNs also cache those assets to be able to respond to similar requests without making a network call to the origin server.
This is achieved by the use of max-age and etag that are included in the headers of the response.
Consumers will reuse assets from their local cache until the max-age passed, which causes them to go to the provider to fetch the resource if changed, or to be told to reuse the existing one when it has not.